Using wget to crawl password-protected websites
We are using SOLR to search pages and documents on some of our client’s websites. SOLR contains the module that is crawling sites and places the website’s contents in the SOLR search repository. Unfortunately, it is not able to crawl password-protected pages of the website.
One of the solutions is to detect SOLR crawlers and open access to the password-protected pages. Such detection should be adequately secured – for instance, limited to specific IPs. Sometimes, however, we are not able to modify the engine of the page we want to crawl. In such a case, we pull the data using wget and feed the results of such crawl to SOLR.
Obtaining information about the login form
If there is a password-protected area, there is also a login form. The first step is to simulate the usage of such a login form through the wget. Let’s start with the browser – go to the login page and fill the login form. Before sending the form, open Developer Tools (Ctrl+Shift+I or F12) and switch to the Network tab.
Once the form is sent, you will see requests that were sent to the server. In most cases, you should focus on the first one.
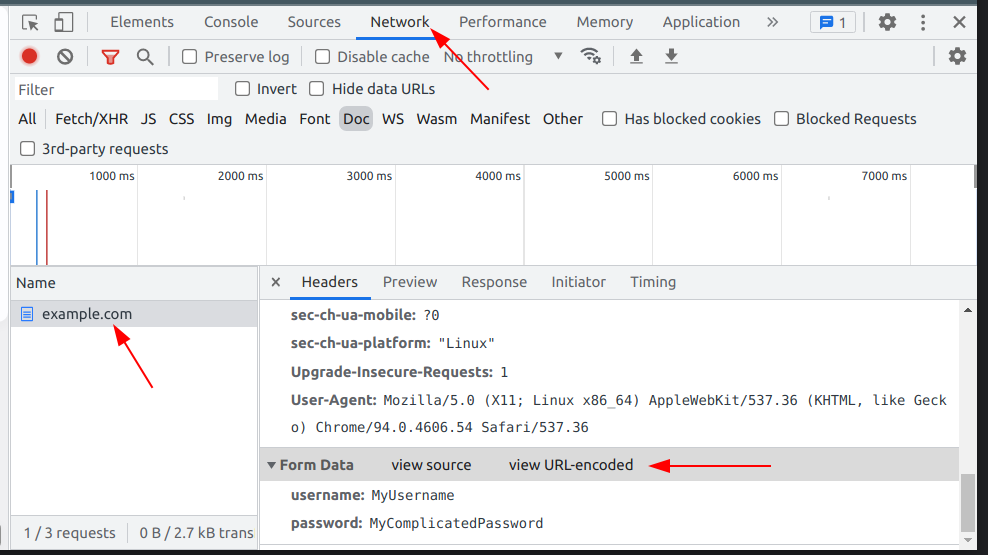
Click on the name of the requested page (in my case – example.com) and scroll down the Headers pane to see Form Data. You should also switch the view to a URL-encoded version in case your username or password contains the characters that should be properly encoded.
In the example above, there are only two fields sent – username and password. In many cases, there are more fields, and you should take care of all of them.
Simulating the login using wget
Now, once we have form fields information, we can simulate the form submission using wget. The thing is that we should not only send the form but also receive cookies provided by the server in response to the request. These cookies are the source of the information that someone is logged in. They carry the session identifiers – we will have to send them back to the server on subsequent requests.
Let’s take a look at the command to execute:
wget --save-cookies example.txt --keep-session-cookies --post-data 'username=MyUsername&password=MyComplicatedPassword' https://example.com
What we’ve got here? We kindly ask wget to save cookies into the ‘example.txt’ file, along with session cookies. We are also sending post data we obtained from the browser – please note that the fields are provided together, divided by the & sign.
Once the command is executed, you should see that the ‘example.txt’ file is created. You can take a look inside – it contains the cookies provided by the server.
The crawling itself
Once we have our session saved in the file, we can use it to crawl the pages we want. We need to provide the cookies file and ask wget to keep the session intact. We are also providing the start page for the crawl and ask wget to perform recursive discovery:
wget --load-cookies example.txt --keep-session-cookies -r https://example.com/protected/
The result of such a crawl is a set of HTML files. Now we can feed them to SOLR and use our search engine also on the password-protected pages.
Side note
The cookies saved in the file are not eternal. Session expires after a specific time of inactivity. If you are performing repetitive crawls (let’s say – once a week or once a month), you will have to repeat the login operation on each execution.
The second important note is that the password to the page is exposed in the script. This is a serious security risk, so the script itself should be properly secured.