Fuzzy search testing – using PostgreSQL compared to Qdrant vector database
I was tasked with the research on fuzzy search possibilities. The goal is to find “similar names” when Customer Service enters a new client into the CRM. Sometimes they misheard the name on the phone. Sometimes the notes are not clear enough. In short – we want to make sure that this is not duplicate.
PostgreSQL provides a wide range of fuzzy search methods. In my tests, I used three of them:
- Similarity search using Trigrams
- Soundex
- Levenshtein distance
Similarity search using trigrams is a method that leverages trigram indexes to perform efficient string matching and similarity calculations. Trigrams are three-character subsequences extracted from strings, and PostgreSQL stores these trigrams in an index structure. By utilizing the trigram index, PostgreSQL can quickly identify similar strings by comparing the common trigrams they share, allowing for tasks like fuzzy text matching, spell correction, and autocomplete suggestions.
Soundex is a phonetic algorithm used in PostgreSQL for indexing and matching words based on their pronunciation. It assigns a code to each word, capturing its primary sound characteristics. When a word is indexed using the Soundex algorithm, it generates a compact representation of its pronunciation.
Levenshtein distance is a measurement of the minimum number of operations required to transform one string into another. In PostgreSQL, the Levenshtein distance function is used to calculate the difference between two strings by counting the number of insertions, deletions, and substitutions needed to convert one string into the other.
On the other hand, I also wanted to check how the Qdrant vector database will do the same with the help of all-mpnet-base-v2 model.
Qdrant is an open-source vector similarity search engine that utilizes embedding models. An embedding model maps high-dimensional data, such as text or images, into lower-dimensional vectors, capturing semantic or contextual information. Qdrant indexes these vectors in a searchable structure, such as an approximate nearest neighbor (ANN) index, allowing for efficient similarity searches.
Qdrant’s workflow involves two main steps: indexing and searching. During indexing, the embedding model is used to convert input data into vectors, which are then stored in the index structure. The index enables fast retrieval and comparison of vectors based on their similarity.
In the search phase, Qdrant takes a query vector as input and quickly identifies the nearest neighbors from the indexed vectors. This is done by utilizing distance metrics like Euclidean distance or cosine similarity to measure the similarity between the query vector and the indexed vectors. Qdrant returns the most similar vectors, allowing users to find relevant matches based on their similarity scores.
Qdrant with open-source embedding models provides several benefits. First, it allows for efficient and scalable similarity search on large-scale datasets. Second, open-source embedding models provide flexibility and the ability to leverage pre-trained models or train custom models for specific use cases. Third, by using embeddings, semantic relationships and contextual information can be captured, enabling more accurate and meaningful similarity comparisons.
Results
Let’s first take a look at the results of searching for the name that is in the database, along with some of variations of the same name. Here I searched for “Matthews K. Martinez“. The name is in the database but without the middle initial – K. Here are results from PostrgreSQL:

As you can see, different methods provide different score metrics, so the code should take it in consideration when selecting the “similar names”.
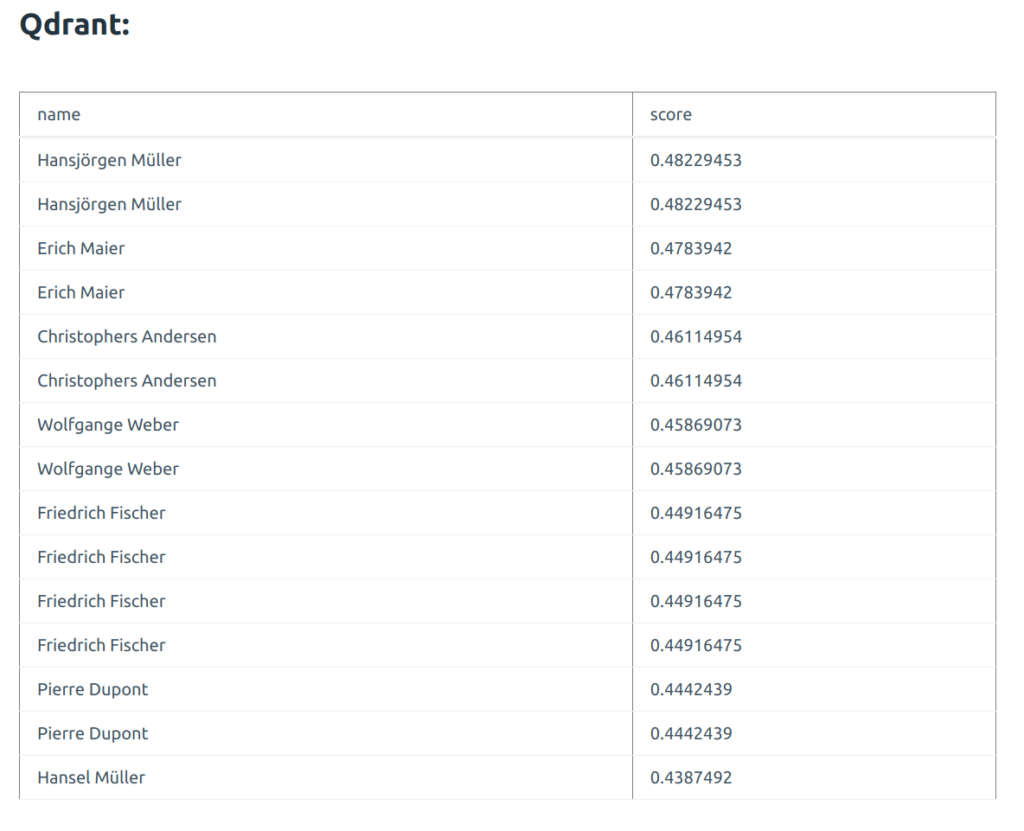
The results form Qdrant look like this:
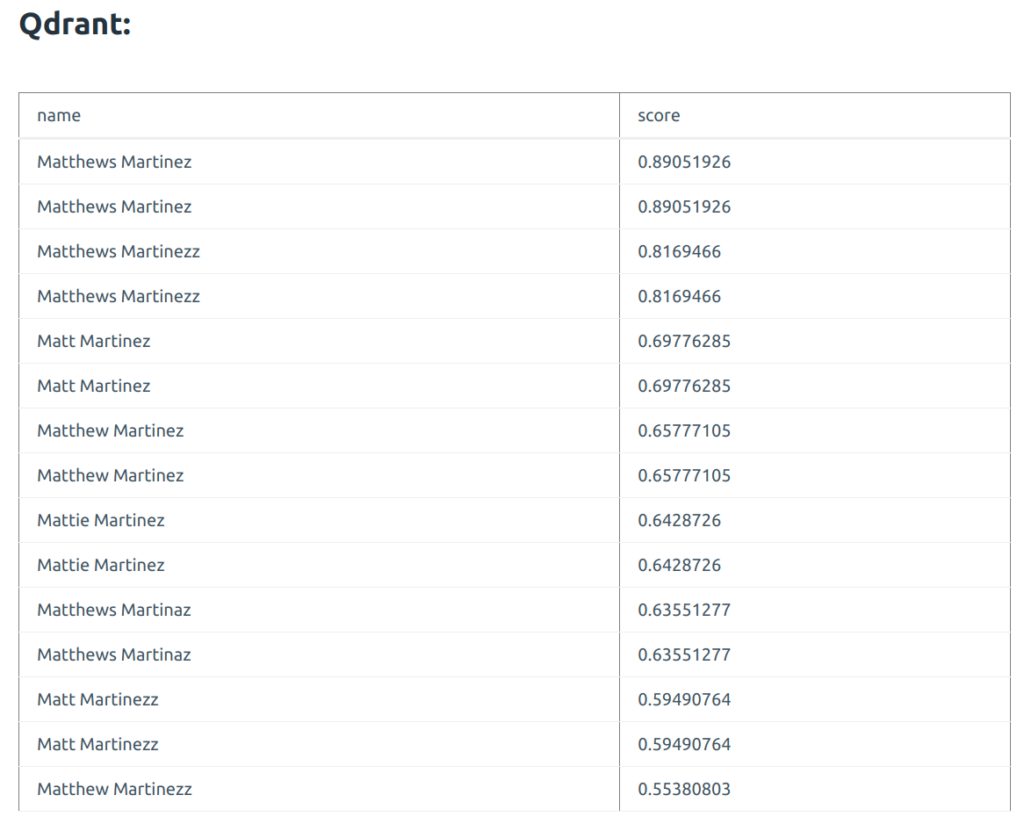
Let’s now search for the name that exists in exactly the same way. Here I search for Peter Hermann:
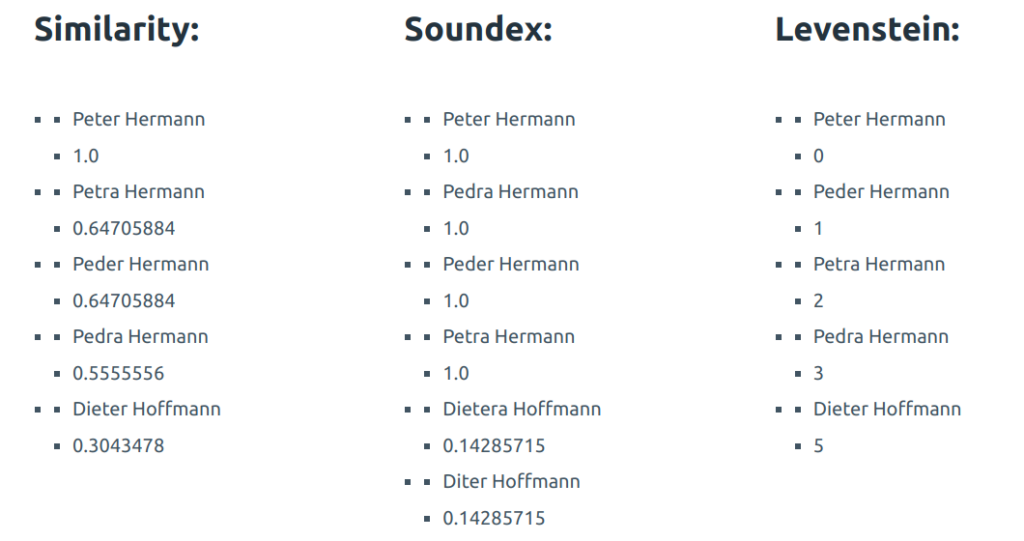
You can see how the scores differ and what are some “distant neighbors” of the name. Here is Qdrant:
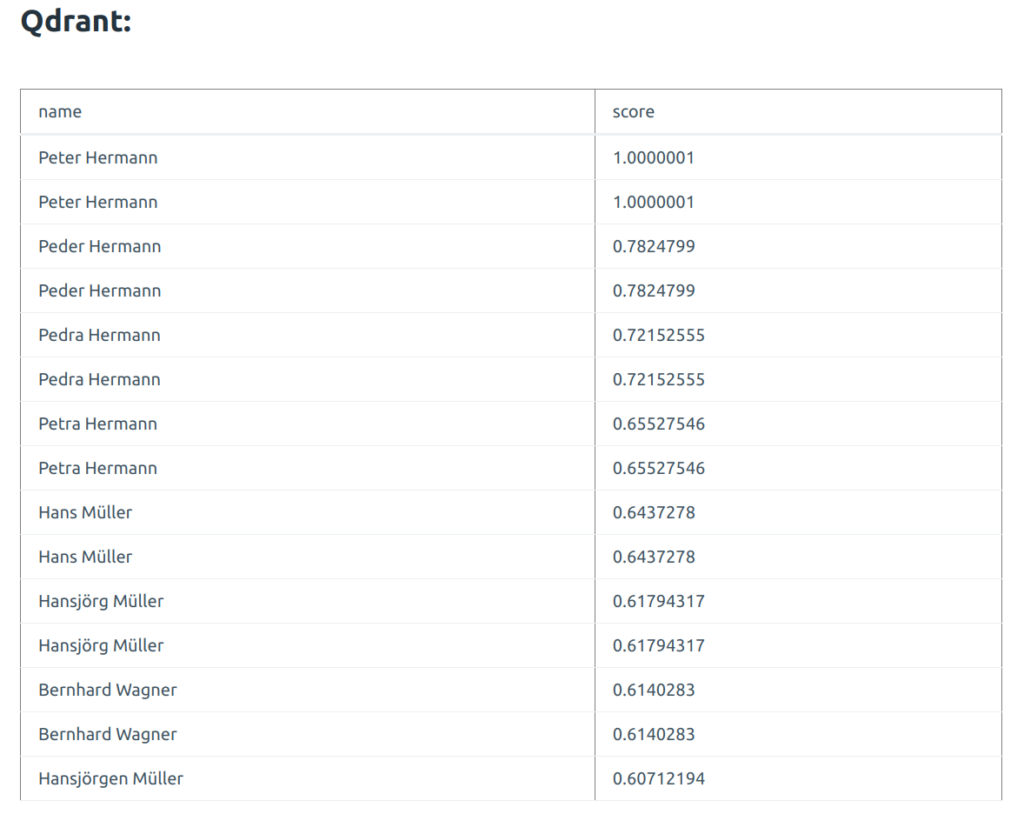
And the final test, what it looks like when I search for something that is not in the database. I searched for Albert Einstein:
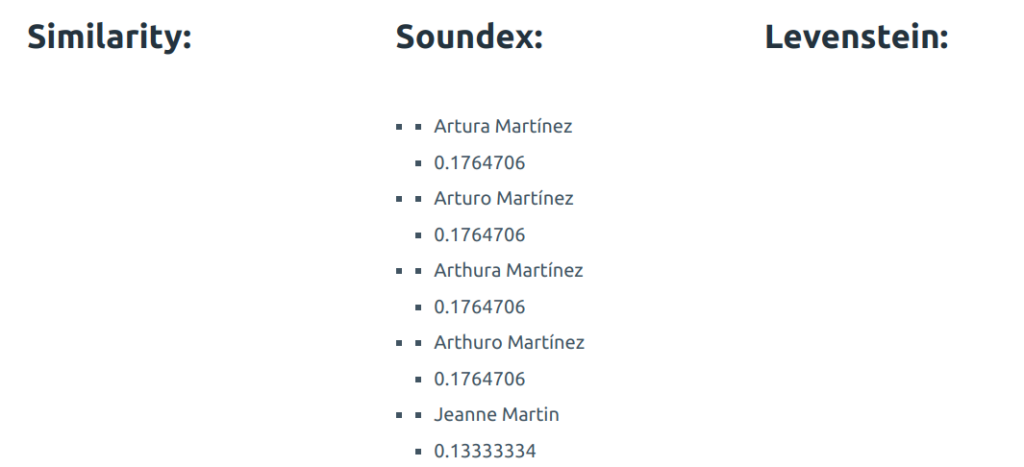
Please note that there are empty results for Similarity and Levenstein distance. In Qdrant we have:
If you want to test it on your own, feel free to use the repo: