OpenAI models fine-tuning considerations
This article is not a fine-tuning how-to. The fine-tuning documentation is available on the OpenAI platform, and it is the first document to be read. In this article, I want to focus on a few less-known topics that are important when you want to fine-tune the model.
In my case, the most useful feature of OpenAI models is their ability to classify based on the text provided by the user. A well-known type of classification is sentiment analysis – we want to detect if given text (e.g. a comment from the blog) falls into Positive, Negative, Neutral, or Mixed sentiment. Such ready-made models for sentiment analysis are available from various sources, so there is no need to fine-tune them unless you have a very specific use case.
On the other hand, for one of our clients, we need to classify comments in one of the areas: are they about staff attitude, technical problems, law-related issues, or product-related questions? This requires a fine-tuned model that will take care of content specific to the area we are working in. This is a specific industry, and comments use language related to the domain.
In our case, we had five areas, and we had to prepare data for the model to fine-tune. This required the staff to assign desired areas to comments manually. Sometimes it was a single area, sometimes, we had more than one.
In the case of OpenAI models, they recommend at least a few hundred examples per category. They also wrote: In general, we’ve found that each doubling of the dataset size leads to a linear increase in model quality. It was easy to find a lot of comments in some of the areas, but it was not that easy for the rest of them. Here the first thing came into play – data augmentation.
Data augmentation
In general, data augmentation is the method of increasing the amount of data in a training dataset by creating slightly modified copies of existing data. For the images, it can be achieved by mirroring them, the introduction of distortions, rotations, and cropping, among other methods. But what about the data for LLM?
Before GPT-3.5, it was not that easy to automatically create new records for augmentation. Now it is much simpler – you can ask the advanced model (GPT-3.5, GPT-4) to rephrase a comment or question while maintaining the meaning. Let’s do it with a simple example.
Let’s assume that we want our model to classify the country to the particular continent it is on. The user may ask: “On which continent is France?” but may also ask the same question in various other ways. Our training data will consist of the list of countries listed with the continents they are in. Since the data for OpenAI training should be JSONL, the training file will look like this:
{"prompt": "On which continent is France?", "completion": " Europe"}
{"prompt": "On which continent is Spain?", "completion": " Europe"}
{"prompt": "On which continent is Japan?", "completion": " Asia"}
...
As you can see, we have only one record per country. This may lead to a situation when a different-phrased question will not be handled properly. So, let’s ask GPT-3.5 what are the other possibilities:
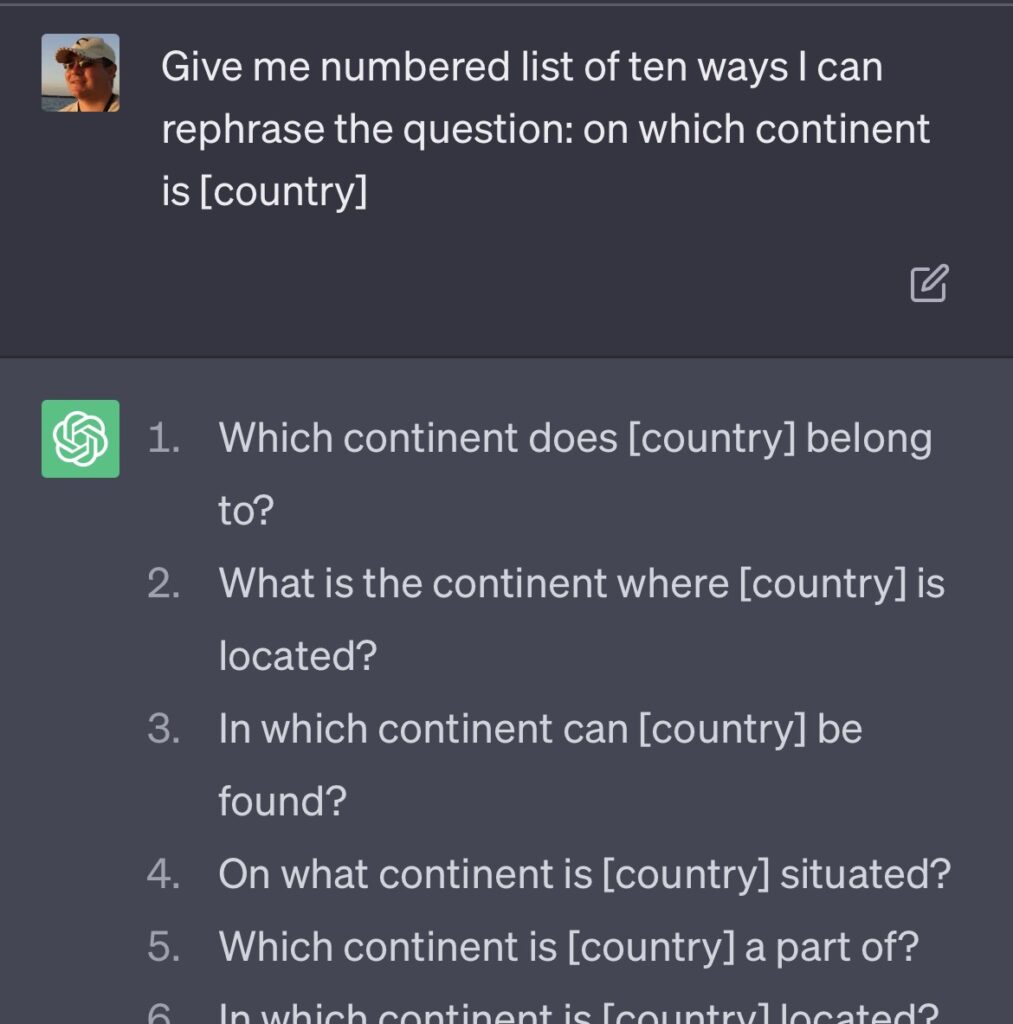
I also asked about the questions without “continent” word:

This way, I got a list of twenty ways to ask a question about the country’s location. My training file now contained twenty-one lines for each country. This is still not that much, but much better than initially.
What are the benefits of data augmentation? Among others:
- I can use a cheaper model for training – because I provide multiple examples, it will not have to be as sophisticated as more complex models to achieve the same. It is cheaper in training and cheaper in usage.
- The model will “understand” questions phrased differently. The actual way in which the user asks the question may not be on my list of augmented questions, but there is a better chance that the intention will be understood.
- The more examples I have for each country, the smaller possibility of mistakes made by the model when answering the question.
Training and validation sets
When running the OpenAI tool to prepare training data, you are asked:
- [Recommended] Would you like to split into training and validation set? [Y/n]
Here lies the trap. You have to be careful with validation sets. Why? Let’s assume that we still work on the Countries and Continents and have a training set containing a single record for each country. When the OpenAI tool prepares training and validation sets, it counts the number of categories (Continents) and randomly selects a proportional number of records for each Continent. The validation data is removed from the training set and placed into the validation set. This means that particular countries will NOT be part of the training data. The model will have no information about them.
It is not a problem in classification, such as sentiment analysis – the fact that the particular sentence was not a part of training should not affect results. Other sentences will fill the gap. But in our simple example, if the information that “France” is on “Europe” will not be provided, the model will not be able to categorize this country in the future. The name of the country and the question itself contain no information about the continent, so there is no way to properly “guess” the answer.
When I trained the ADA model with training and validation set on non-augmented data, and I moved France to the training set, here is what I received:
- On which continent is France? -> The country is divided
- Where is France? -> _________ (a few spaces as an answer)
This means that you have to skip the validation set creation when each record counts for the small training sets.
On the larger set with augmented data, I also suggest not relying on the OpenAI tool to select the data for the validation set because it can “draw” more records related to the particular country and less to the other. When creating augmented data like in the example above, for each country, I would randomly select three of the twenty-one augmented records and move them to the validation set. This will give a representation of each country in the validation set and will also give different types of questions in this set.
Selecting the data for fine-tuning
As I wrote in my production example above, we had a situation in which we had many (tens of thousands) sentences in two categories but a small number of sentences in the other three. How to select data for fine-tuning in such a case?
The first rule is to select sentences that lie in one of the categories only. The more apparent it is in which category the given sentence is, the better. One way or another, the trained model will have to deal with ambiguous sentences in the future, so don’t confuse it in the training phase.
The second rule – the shorter the sentence, the better. Not only because you pay for the number of tokens (and you are paying for them!) but also because shorter sentences are more to the point and set the proper bias on the model. If it looks like a duck, swims like a duck, and quacks like a duck, then it probably is a duck. No need to add lengthy sentences that got a lot of filler text. The model will deal with it.
The third one – if there are not enough examples for a given category – use GPT-3.5 or GPT-4 to generate more. It will cost you at the moment of generation, but it will result in a much better-fine-tuned model in the end. Of course, such an augmented training set (sentences generated by GPT) has to be reviewed manually first!
In practice, we had to perform a set of tests. We tried various training sets, used the rest of the training data as our validation set, and observed the results. The above rules produced the best results.